edge-detector
Edge Detection From the Ground Up
Shown below is a gif that has been run through my twist on the famous Canny edge detector. Read more to see details about my unique implementation which uses the edge gradient theta value to construct a heat map which superimposes color (corresponding to edge orientation/slope) onto the Canny edge detected image.
This repo contains some edge detection algorithms and tools, as well as a collection of simpler image processing algorithms, all implemented from scratch in python. Image handling is done with the PIL library and computation is with NumPy. Here is a YouTube video demonstrating some of the results.
Table of Contents
Edge Detection
Blur Algorithms
Cropping and Resizing Algorithms
Other Algorithms
Sobel Edge Detection
Sobel edge detection is an algorithm which highlights the edges of an image based on intensity changes. The first step in this is to greyscale the image. This allows us to map the color values as intensities. From here, we apply noise reduction (I used imports from my Gaussian and median blur implementations). Finally we approximate the changes in intensity to identify edges. These edges are simply discrete derivative approximations made through preset kernels that are convolved with the image. For more info on how Sobel edge detection works, see here.
My implementation of the Sobel edge detection algorithm is in sobel_edge_detector.py. To run this file, run this from the root: python3 src/edge_detection_algorithms/sobel_edge_detector.py -f [FILEPATH], where the filepath is from the root (e.g. images/luffy.py). On the left is the original image I used (mugen.jpg) and on the right is it run through the Sobel edge detector.
{kind=link}

As can be seen, the edges are highlighted with varying intensity and thickness based on the strength and range of the changes in color. The Sobel edge detection method is useful for visualizing edges, but because it does not show thin edges with applicable detail, it is not as useful in general.
I have also implemented a Sobel gif maker (sobel_gif_maker.py), where you can input a gif in the same way as sobel_edge_detector.py. Every frame is run through the algorithm, and the resulting gif is saved to canny_animations. Below is an example of running sobel_gif_maker.py on violet.gif.
{kind=link}

Canny Edge Detection
Canny edge detection takes our implementation one step further. By completely identifying edges as existent or not, it gives a clear picture of where exactly our edges in an image may be, which is very useful for computation. Below is an example of my implementation of Canny edge detection applied on forgers.jpg.
{kind=link}

To achieve this result, we must apply some operations on our Sobel edge detected image. Consider mugen.jpg, which we used before. After applying Sobel edge detection, our first goal is to remove the thicker lines and make them thin, showing only one change point. This can be achieved by an operation called non-maximum suppression. For a given pixel, we calculate the direction that its gradient changes (using NumPy’s specialized arctan2 function), and use this angle to check the perpendicular neighbors of the pixel. If the pixel’s change intensity is larger than its neighbors, then we keep the value. Otherwise, we set it to zero. By doing this, we achieve thinner edges and remove some stray noise that the noise reduction may not have initially caught. The result of this is shown below.

After this, we put our non-maximum suppressed image through a double threshold filter. Based on the intensities in the image, we choose a high and low threshold. Pixels with intensity values above the high threshold are now set to the max and pixels below the low one are set to zero. With this, we eliminate some false edges in our image that stem from noise. The result of this operation on mugen.jpg is shown below (with the non-maximum suppressed image on the left and the double threshold image on the right).

Above, bright edges are “strong” and dimmer edges are “weak”. The final process that we put our image through is hysteresis. We simply iterate through the image, finding every weak pixel. If a weak pixel borders a strong pixel, we make it strong. If it does not, we set its intensity to 0, thus removing more extra noise. The final result of this operation applied on mugen.jpg is shown below (with the double threshold image on the left and the post-hysteresis image on the right).

Canny edge detection has many more small steps, optimizations, and alternate approaches which I did not cover. Additionally, my verbal explanation of some of the steps does not do justice to how neat some of the math actually ends up being. To learn more about the algorithm, I encourage that you read here.
My implementation of the Canny edge detector is in canny_edge_detector.py. To run this file, run this from the root: python3 src/edge_detection_algorithms/canny_edge_detector.py -f [FILEPATH] --no-color, where the filepath is from the root (e.g. images/luffy.py).
You can see how the Canny edge detector looks on various images (before and after) in canny_results. I have also implemented a Canny gif maker (canny_gif_maker.py), where you can input a gif in the same way as canny_edge_detector.py. Every frame is run through the algorithm, and the resulting gif is saved to canny_animations. Below is an example of running canny_gif_maker.py on araragi.gif.
{kind=link}

Canny Edge Detection with Theta Color Gradient
I decided to add my own spin on the Canny edge detection algorithm. Because I already calculated the angle of the intensity gradient at every given pixel in my implementation of non-maximum suppresion, I chose to use this value to assign “strong” edges certain color values instead of the white that the original algorithm assigns. Horizontal gradients yield cooler colors and vertical gradients yield warmer colors (the rest is linearly interpolated). The details for converting theta into an RGB value can be found in helper_rainbow_fill.py. By doing this, I was able to create a more readable output where edge direction is immediately aparent from color.
I’ve made it so simply running canny_edge_detector.py will give color (unless you specify the --no-color parameter), so running the file as previously specified should work. The same applies for canny_gif_maker.py. Below is mugen.jpg with my Canny edge detector run on it (--no-color on the left, --color on the right).

The same operation on forgers.jpg is shown below. See canny_haikyuu_spike_colored.gif for the result when we run haikyuu_spike.gif through canny_gif_maker.py with this variation.
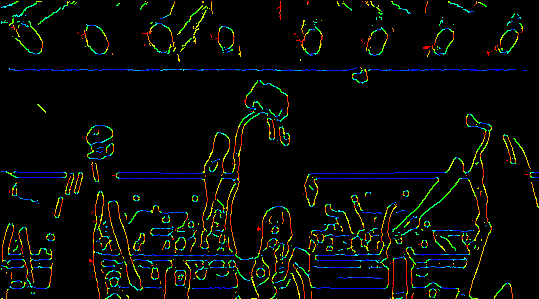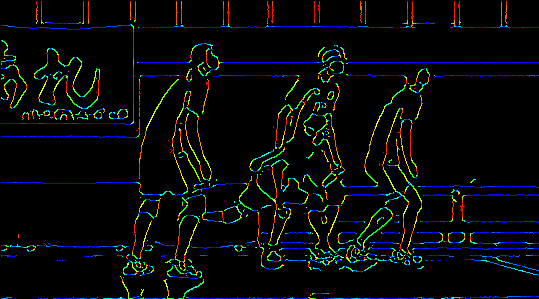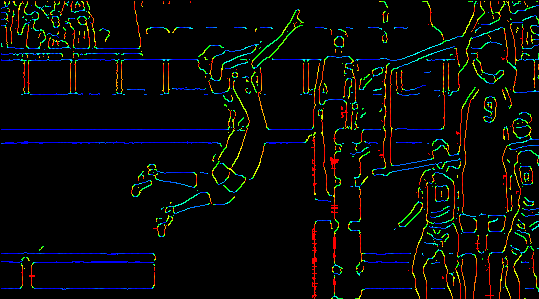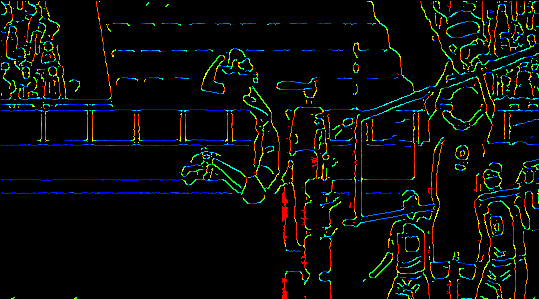{kind=link}
{kind=link}

As mentioned above, I made it so that canny_gif_maker.py applies this by default. Below is an example of running this on mob.gif.
{kind=link}

Gaussian Blur
Gaussian blur is a blur algorithm which maintains detail well due to assigning weights based on distance from the original pixel. It makes use of the Gaussian function (also known as ‘normal distribution’ and ‘bell curve’) to assign weights when blurring per-pixel. When looking at how to convolve a pixel’s surrounds to its own new value, we look to the Gaussian function, centered around this pixel in 2 dimensions, to assign weights for how each of the surrounding pixels will contribute to the center pixel’s new RGB values.
This works because when stretching out to infinity, the integral under a Guassian function will be 1.00. Of course, after around 3 standard deviations, the effect is negligible. So, the algorithm that I’ve attempted to implement from scratch uses a kernel that is constructed from the Gaussian function in 2 dimensions (shown below).

The kernel is then normalized so the sum of its elements is 1.00 per color and convolved (using the Hadamard product) with the matrix containing the corresponding pixel and its surroundings. This value is stored in the pixel’s corresponding spot in the new image. The values are then summed up per color in the RGB 1 x 3 matrix, which finally yields the value for one pixel. This processes is repeated on every pixel of the image. To read more about Gaussian blur, see here.
My implementation of the Gaussian blur algorithm is in gaussian_blur.py. To run this file, run this from the root: python3 src/blur_algorithms/gaussian_blur.py -f [FILEPATH] -s [SIGMA_VALUE], where the filepath is from the root (e.g. images/luffy.py) and sigma is the strength (typically an integer between 1 and 10 inclusive for reasonable results).
Larger files and sigma values take significantly longer beause of the computationally expensive nature of running Gaussian blur from scratch. Surely, PIL and other image handling libraries utilize advanced optimization techniques. As these implementations are for my own educational purposes and are meant to be semantically understandable, I will leave things as are. Below is an example of running (from the root) python3 src/blur_algorithms/gaussian_blur.py -f images/luffy.jpg -s SIGMA for SIGMA ∈ [1, 2, 3, 4] along with the original image (i.e. SIGMA = 0).
 </img>
</img>
Box Blur
Box blur is the most simple blur algorithm. It takes the average RGB values of all pixels within a given distance of the target pixel. Because it uses a simple average, it is quite easy to implement iteratively, where we just take the arithmetic mean of all the pixels in the needed range. This implementation is in box_blur.py. To run this file, run this from the root: python3 src/blur_algorithms/box_blur.py -f [FILEPATH] -r [RADIUS], where the filepath is from the root (e.g. images/luffy.py) and radius corresponds to the range from which we take the mean.
Alternatively, we can use a moving window identically to the Gaussian Blur algorithm where our kernel matrix consists of uniform values to represent identical weights in a “weighted” average. To learn more about box blur, see here. A moving window kernel where our given radius is 1 is shown below:
 </img>
</img>
This implementation (made because most of the groundwork was laid in gaussian_blur.py) can be found in box_blur_moving_window.py. This file may be run in the same way as box_blur.py.
Below is an example of running (from the root) python3 src/blur_algorithms/blur_algorithms/box_blur.py -f images/luffy.jpg -r RADIUS for RADIUS ∈ [3, 6, 9, 12] along with the original image (i.e. RADIUS = 0). These radius values roughly correspond to the Gaussian blur SIGMA values of 1, 2, 3, and 4 because their respective kernel sizes are equal in my implementation (which used a standard deviation of 3 for the Gaussian distribution kernel).
 </img>
</img>
As can be seen above, even though the blur factors are similar, many details are lost in this blur method compared to Gaussian blur. So though it is less computationally expensive, it retains much less detail.
Median Blur
Median blur is very similar to box blur in that it does a very simple operation over a certain range surrounding the pixel of interest to calculate its new value. The difference is that it will take a median for each of the R, G, and B values over the given range rather than their mean. As such, my implementation, which is in median_blur.py, is very similar to box_blur.py save for the calculation of the pixel RGB value (which is a median instead of a mean). To run this file, run this from the root: python3 src/blur_algorithms/median_blur.py -f [FILEPATH] -r [RADIUS], where the filepath is from the root (e.g. images/luffy.py) and radius corresponds to the range from which we take the median.
Because we are taking a median, severe outliers do not at all contribute to the image. Sporadic RGB values (which often correspond to “wrong” color pixels in given ranges) are completely ignored in the median calculating process so long as the majority of values in the range are consistent in their RGB values. As such, this blur method is very good at removing unwanted noise from images. Shown below is forgers_noise.jpg (the result of running forgers.jpg through an image noise adder) before and after running median blur with radius 2 (run python3 src/blur_algorithms/median_blur.py -f images/forgers_noise.jpg -r 2 from root).
{kind=link}

As can be seen above, there is actually a quite remarkable amount of noise correction that seems to occur from simply taking the median RGB values. Running median blur on the same image with noise that is not monochronic still yields quite good results, as seen below (run python3 src/blur_algorithms/median_blur.py -f images/forgers_noise_2.jpg -r 2 from root).

We can compare this to other blur algorithms to show its supremacy in removing noise. Below (from top to bottom) are the median blur, Gaussian blur, and box blur algorithms with RADIUS (SIGMA for Gaussian blur) values of 0, 1, 2, and 3. As can be seen, median blur completely eliminates noise almost immediately, though edge clarity is lost. Still, even with RADIUS = 1, median blur outperforms the other algorithms greatly.

It should also be noted that due to our calculation of median not requiring a moving window of any sort, this algorithm is very fast when compared with Gaussian blur, for instance.
Simple Crop
Using matrices in R^n, it is quite easy to cut out a ‘rectangle’ using indices. For image cropping, we take the array representation of the image and simply index it as img_arr[row_start : row_end + 1, col_start : col_end + 1]. The implementation for this is in the simple_crop function from simple_crop.py.
In simple_crop_gui.py, I have made a simple graphical user interface for cropping in pygame. To run the file, run this from the root: python3 src/resize_algorithms/simple_crop_gui.py -f [FILEPATH], where the filepath is from the root (e.g. images/luffy.py). Below is an example use of the GUI.

Nearest Neighbor Interpolation
A common and fast method for image resizing lies in nearest neighbor interpolation. This method resizes the new image according to a scale, and maps the pixel value to its (linearly) corresponding position on each axis to the original image. Through this, the image scales in a discrete manner. Some details are lost when the scale is less than 1.00, and scaling up in size causes blocks and streaks to occur due to there being no upscaling correction. My implementation of this method is in nearest_neighbor_interpolation.py.
To run this file, run this from the root: python3 src/resize_algorithms/nearest_neighbor_interpolation.py -f [FILEPATH] -s [RESIZE FACTOR], where the filepath is from the root (e.g. images/luffy.py) and the resize factor is a float greater than zero corresponding to scale. Shown below (from left to right) is this algorithm run with resizing factors of 0.5, 1, and 2 on freedom.jpg.
{kind=link}

Bilinear Interpolation
The blocky upscaling of nearest neighbor interpolation leaves much to be desired when we upscale to larger sizes. The pixelated nature of the originally smaller image becomes very apparent, after all. To mitigate this effect, we can use bilinear interpolation. This resizing method essentially eliminates apparent blockiness by linearly interpolating for each pixel that corresponds to a point in between discrete RGB values from the original image. Mathematically, this idea is actually quite difficult to explain without diagrams and many redundant equations. See here for more about bilinear interpolation.
My implementation of this algorithm can be found in bilinear_interpolation.py. As the first paragraph of the wikipedia link describes, I linearly interpolated with weighted averages one axis at a time, using NumPy’s rotation method to increase the efficiency of the implementation. To run this file, run this from the root: python3 src/resize_algorithms/bilinear_interpolation.py -f [FILEPATH] -s [RESIZE FACTOR], where the filepath is from the root (e.g. images/luffy.py) and the resize factor is a float greater than 1.
Now, let us see what kind of differences that bilinear interpolation provides to image resizing. Below, we have two images, both of which are the results of running resizing algorithms (with x5 resizing) on eren.jpg. To the left, we have the nearest neighbor interpolation result (run python3 src/resize_algorithms/nearest_neighbor_interpolation.py -f images/eren.jpg -s 5 from root). To the right is the bilinear interpolation result (run python3 src/resize_algorithms/bilinear_interpolation.py -f images/eren.jpg -s 5 from root).
{kind=link}

As can be seen above, there is clearly some filled in smoothness when comparing the right image to the left. This is a result of bilinear interpolation mitigating most of the jarring transition that would occur between pixel changes.
Box Sampling
When we use nearest neighbor interpolation to reduce the size of an an image, we are essentially picking (roughly) equidistant lattice points from the original image to map onto the new image. Because the input to the downsized image only consists of said lattice points, we lose more information the smaller our resizing factor is (by virtue of there being less lattice points), giving rise to aliasing. For example, below (to the left) is forgers.jpg with a 0.2 resize scale (run python3 src/resize_algorithms/nearest_neighbor_interpolation.py -f images/forgers.jpg -s 0.2 from root). Notice how the image lacks some details and feels “grainy”.
A solution to this is box sampling. We use all of the lattice points to create a grid of boxes (each one being a rectangular section of pixels from the original image) from which we take average RGB values. With each box corresponding to a pixel in the downsized image, we assign said pixel the average RGB value of the box. With this method, all of the pixels in the original image contribute to the downsized image, effectively introducing a downscale that drastically decreases lost info. Box sampling makes a large difference, as can be seen in its application to the same image (right) below.
<img src="readme_screenshots/box_sampling_sxf.png", alt="Forgers Box Sampling">
My implementation of this algorithm can be found in box_sampling.py. To run this file, run this from the root: python3 src/resize_algorithms/box_sampling.py -f [FILEPATH] -s [RESIZE FACTOR], where the filepath is from the root (e.g. images/luffy.py) and the resize factor is a non-zero, positive float less than 1.
Below we have two images. On the left is gintama.jpg run through nearest_neighbor_interpolation.py with a resize factor of 0.25. On the right is the same image run through box_sampling.py with the same resize factor of 0.25.
{kind=link}
<img src="readme_screenshots/box_sampling_gintama.png", alt="Box Sampling Demonstration">
As can be seen, the right image (box sampling) retains much more detail and smoothness by taking all of the original image’s pixels into account as opposed to the left one (nearest neighbor interpolation).
Greyscale
To fully greyscale an image, we take a given pixel and set all of its RGB values to their cumulative average. As such, a pixel, < R, G, B > would become < (R + G + B) / 3, (R + G + B) / 3, (R + G + B) / 3 >. If we want to implement this operation with varying greyscale strengths, we need only make a weighted average between the original pixel and the fully grey one. This, benig a linear relationship, would directly apply a strength (from 0 to 1) on the image to grey it by that factor.
My implementation of this algorithm can be found in greyscale.py. To run this file, run this from the root: python3 src/src/other_algorithms/greyscale.py -f [FILEPATH] -s [STRENGTH], where the filepath is from the root (e.g. images/luffy.py) and the strength is a float from 0 to 1. Below is an example of this algorithm run on nichijou.jpg with strengths (top left, top right, bottom left, bottom right) of 0, 0.33, 0.67, and 1.
{kind=link}

Brightness
Brightness can also be applied very simply. All we need to do is increase all of the RGB values in a given pixel by a constant, capping off the values at 255 above (i.e. if the value exceeds 255, set it at 255) and 0 below. By introducing a brightness constant $b$, which ranges from -1 to 1, as the portion of 255 by which to add/subtract to each RGB value. So, iterating through each pixel’s RGB values, we apply: $C = C_0 + b * 255$, then correct for values above 255 and below 0.
My implementation of this algorithm can be found in brightness.py. To run this file, run this from the root: python3 src/src/other_algorithms/brightness.py -f [FILEPATH] -b [BRIGHTNESS FACTOR], where the filepath is from the root (e.g. images/luffy.py) and the brightness factor is a float between -1 and 1 (negative values to darken and positive values to brighten). Below is an example of this algorithm run on saitama.jpg, with brightness factors of -0.5, -0.25, 0, 0.25, and 0.5 (from left to right).
{kind=link}
